内核漏洞挖掘技术系列(6)——使用AFL进行内核漏洞挖掘(2)

这是内核漏洞挖掘技术系列的第十三篇(本篇文章为翻译)。
第一篇:内核漏洞挖掘技术系列(1)——trinity
第二篇:内核漏洞挖掘技术系列(2)——bochspwn
第三篇:内核漏洞挖掘技术系列(3)——bochspwn-reloaded(1)
第四篇:内核漏洞挖掘技术系列(3)——bochspwn-reloaded(2)
第五篇:内核漏洞挖掘技术系列(4)——syzkaller(1)
第六篇:内核漏洞挖掘技术系列(4)——syzkaller(2)
第七篇:内核漏洞挖掘技术系列(4)——syzkaller(3)
第八篇:内核漏洞挖掘技术系列(4)——syzkaller(4)
第九篇:内核漏洞挖掘技术系列(4)——syzkaller(5)
第十篇:内核漏洞挖掘技术系列(5)——KernelFuzzer
第十一篇:内核漏洞挖掘技术系列(6)——使用AFL进行内核漏洞挖掘(1)
第十二篇:内核漏洞挖掘技术系列(7)——采用静态模式匹配挖掘linux内核double fetch漏洞
之前在本系列的第十一篇文章:内核漏洞挖掘技术系列(6)——使用AFL进行内核漏洞挖掘(1)中和大家分享了两个使用AFL进行内核漏洞挖掘的工具。这两个工具的实现都比较复杂,那么有没有比较简单的将AFL应用于内核漏洞挖掘的方法呢?这里为大家翻译一篇cloudflare使用AFL对netlink进行fuzz的博客,这篇博客中采用的方法相比之前介绍的方法可以说是更“轻量级”的,也更好理解和上手。希望读者能有所收获。
前言
有一段时间我一直想做基于代码覆盖率的fuzz。fuzz是一种强大的测试技术:自动化的程序将半随机的输入发送到测试程序以找到触发错误的输入。fuzz在查找C/C++程序中的内存损坏错误时特别有用。
通常情况下建议选择一个众所周知但之前没有很多人fuzz过的主要功能是解析的库进行fuzz。以前像libjpeg,libpng和libyaml这样的库都是完美的目标。如今找到一个容易的目标更难————它们似乎都已经被fuzz过了。软件越来越安全了,这是好事。我没有选择用户空间的目标,而是选择了Linux内核netlink系统。
netlink是一个由ss/ip/netstat等工具使用的Linux内部的设施。它用于底层网络任务中————配置网络接口,IP地址,路由表等。这是一个很好的目标:它是内核的一个不起眼的部分,并且自动生成有效的输入相对容易。最重要的是,我们可以在此过程中学到很多关于Linux内部的知识。不过netlink中的错误不会产生安全问题————netlink套接字通常需要特权访问。
在这篇文章中,我们将运行AFL,使我们的netlink shim程序在自定义的Linux内核上运行(在计算机编程中shim是一个小型库,可透明地截取API,更改传递的参数,处理操作本身,或将操作重定向到别处)。所有这些都在KVM虚拟化的环境中运行。
这篇博客是一个教程。通过易于遵循的指示,你应该能够快速复制结果。你只需要一台运行Linux的机器和20分钟时间。
前人的工作
我们将要使用的技术正式的说法是“基于代码覆盖率的fuzz”。有很多相关研究:
Dan Guido的The Smart Fuzzer Revolution,以及LWN关于它的文章
j00ru的Effective file format fuzzing
Robert Swiecki开发的honggfuzz,是一个现代化的功能丰富的基于代码覆盖率的fuzzer
ClusterFuzz
Fuzzer Test Suite
很多人都fuzz过Linux内核。最重要的是下面两项研究(下面提到的两个工具在内核漏洞挖掘技术系列文章中已经介绍过了):
由Dmitry Vyukov编写的syzkaller(又名syzbot)是一个非常强大的能够持续集成运行的内核fuzzer,它已经发现了数百个问题。这是一个很棒的fuzzer,它甚至会自动报告错误!
Trinity fuzzer
我们将使用AFL,每个人最喜欢的fuzzer。AFL由Michał Zalewski开发,以易用,快速和非常好的变异逻辑而闻名。这是人们开始fuzz之旅的完美选择!
如果您想了解有关AFL的更多信息,请参阅这几个文件:
Historical notes
Technical whitepaper
README
基于代码覆盖率的fuzz
基于代码覆盖率的fuzz原理是反馈回路:
例如,假设输入测试是hello。fuzzer可能会将其变为多种测试用例,例如:hEllo(位翻转),hXello(字节插入),hllo(字节删除)。如果这些测试中的任何一个产生新的代码覆盖,那么它将被优先用作下一次fuzz的测试用例。
有关如何完成变异以及如何有效地比较数千个程序运行的代码覆盖率报告的细节问题是fuzzer最关键的地方。阅读AFL的技术白皮书了解细节。
从二进制文件报告的代码覆盖率非常重要。fuzzer根据它对测试用例进行排序,并确定最有希望的测试用例。没有代码覆盖率信息进行fuzz就像是盲人摸象。
通常在使用AFL时我们需要对目标代码进行插桩,以便以和AFL兼容的方式报告代码覆盖率。但我们想要fuzz内核,不能直接用afl-gcc重新编译它。这里将使用一个小技巧:我们将准备一个二进制文件,让AFL认为它是用它的工具编译的。这个二进制文件将报告从内核中提取的代码覆盖率。
内核代码覆盖率
内核至少有两个内置的代码覆盖率机制——GCOV和KCOV:
Using gcov with the Linux kernel
KCOV: code coverage for fuzzing
KCOV的设计考虑了fuzz,因此我们将使用它。使用KCOV非常简单。我们必须使用正确的设置编译Linux内核。首先,启用KCOV内核配置选项:
cd linux
./scripts/config \
-e KCOV \
-d KCOV_INSTRUMENT_ALLKCOV能够记录整个内核的代码覆盖率。可以使用KCOV_INSTRUMENT_ALL选项进行设置。缺点是它会减慢我们不想分析的内核部分,并且会在我们的fuzz中引入噪声(降低稳定性)。对于内核fuzz的初学者,禁用KCOV_INSTRUMENT_ALL并有选择地在我们实际想要分析的代码上启用KCOV。现在,我们专注于netlink系统,所以让我们在整个net目录树上启用KCOV:
find net -name Makefile | xargs -L1 -I {} bash -c 'echo "KCOV_INSTRUMENT := y" >> {}'更完美的情况是只为我们真正感兴趣的几个文件启用KCOV。但是netlink遍及网络栈的代码,我们今天没有时间进行微调。
有了KCOV,接下来添加“kernel hacking”配置,这将增加报告内存损坏错误的可能性。参考readme中syzkaller建议的选项列表(最重要的是KASAN)。
使用这样的配置,我们可以编译启用KCOV和KASAN的内核。我们将在kvm中运行内核。我们将使用virtme帮助我们设置环境,需要下面这几项配置:
./scripts/config \
-e VIRTIO -e VIRTIO_PCI -e NET_9P -e NET_9P_VIRTIO -e 9P_FS \
-e VIRTIO_NET -e VIRTIO_CONSOLE -e DEVTMPFS ...(完整列表请参阅readme)
如何使用KCOV
KCOV非常易于使用。首先,请注意代码覆盖率记录在每个进程的数据结构中。这意味着必须在用户空间进程中启用和禁用KCOV,并且无法记录例如中断处理这样的非任务事项的代码覆盖率。这对我们的需求来说完全没问题。
KCOV将数据报告给环形缓冲区。设置非常简单,请参阅我们的代码。然后你可以使用一个简单的ioctl启用和禁用它:
ioctl(kcov_fd, KCOV_ENABLE, KCOV_TRACE_PC);/* profiled code */ioctl(kcov_fd, KCOV_DISABLE, 0);之后环形缓冲区会包含启用KCOV的内核代码的所有基本块的%rip值列表。要读取缓冲区,请运行下面的代码:
n = __atomic_load_n(&kcov_ring[0], __ATOMIC_RELAXED);for (i = 0; i < n; i++) {
printf("0x%lx\n", kcov_ring[i + 1]);}使用像addr2line这样的工具可以将%rip解析为对应的源代码中的那一行。我们不需要它,原始的%rip值对我们来说已经足够了。
将KCOV发送到AFL
下一步是欺骗AFL。请记住,AFL需要一个特制的可执行文件,但我们想要提供内核代码覆盖率。首先让我们了解一下AFL的工作原理。
AFL设置一个64K 8位的数组。该内存区域称为shared_mem或trace_bits,并与跟踪的程序共享。数组中的每个字节都可以被认为是检测代码中特定(branch_src,branch_dst)对的命中计数器。
重要的是要注意AFL更喜欢随机分支标签而不是重用%rip值来识别基本块。这是为了增加熵——我们希望数组中的命中计数器均匀分布。AFL使用的算法如下:
cur_location = <COMPILE_TIME_RANDOM>;shared_mem[cur_location ^ prev_location]++; prev_location = cur_location >> 1;在使用KCOV的情况下没有每个分支的编译时随机值。我们将使用哈希函数从KCOV记录的%rip生成统一的16位数。这就是如何将KCOV报告提供给AFL shared_mem数组的代码:
n = __atomic_load_n(&kcov_ring[0], __ATOMIC_RELAXED);uint16_t prev_location = 0;for (i = 0; i < n; i++) {
uint16_t cur_location = hash_function(kcov_ring[i + 1]);
shared_mem[cur_location ^ prev_location]++;
prev_location = cur_location >> 1;}从AFL读取测试数据
最后,我们需要实际编写调用netlink接口的测试代码!首先,我们需要从AFL读取输入数据。默认情况下,AFL将测试用例发送到stdin:
/* read AFL test data */char buf[512*1024];int buf_len = read(0, buf, sizeof(buf));Fuzzing netlink
然后我们需要将此缓冲区发送到netlink套接字。但我们对netlink的工作原理一无所知!好吧,让我们使用前5个字节的输入作为netlink协议和组ID字段。AFL将找出并猜测这些字段的正确值。简化的代码如下:
netlink_fd = socket(AF_NETLINK, SOCK_RAW | SOCK_NONBLOCK, buf[0]);struct sockaddr_nl sa = {
.nl_family = AF_NETLINK,
.nl_groups = (buf[1] <<24) | (buf[2]<<16) | (buf[3]<<8) | buf[4],};bind(netlink_fd, (struct sockaddr *) &sa, sizeof(sa));struct iovec iov = { &buf[5], buf_len - 5 };struct sockaddr_nl sax = {
.nl_family = AF_NETLINK,};struct msghdr msg = { &sax, sizeof(sax), &iov, 1, NULL, 0, 0 };r = sendmsg(netlink_fd, &msg, 0);if (r != -1) {
/* sendmsg succeeded! great I guess... */}基本上就是这样!为了更快,我们将它包装在一个模仿AFL fork server逻辑的循环中。我将跳过此处的解释,请参阅代码了解详细信息。我们的AFL-to-KCOV shim的代码如下所示:
forksrv_welcome();while(1) {
forksrv_cycle();
test_data = afl_read_input();
kcov_enable();
/* netlink magic */
kcov_disable();
/* fill in shared_map with tuples recorded by kcov */
if (new_crash_in_dmesg) {
forksrv_status(1);
} else {
forksrv_status(0);
}}如何运行自定义内核
我们遗漏了一个重要的部分——如何运行我们构建的自定义内核。有三种选择:
native:可以在本机上启动构建的内核并fuzz它。这是最快的,但如果fuzzer成功找到bug机器将崩溃,可能会丢失测试数据。应该避免这样的方法。
uml:我们可以将内核配置为以用户模式Linux运行。运行UML内核不需要任何权限。内核只运行用户空间进程。UML非常酷,但遗憾的是它不支持KASAN,因此减少了查找内存损坏错误的可能性。而且UML是一个非常神奇的特殊环境,在UML中发现的错误可能与真实环境无关。有趣的是,Android network_tests框架使用UML。
kvm:我们可以使用kvm在虚拟化环境中运行我们的自定义内核。这就是我们要做的。
使用virtme可以避免创建专用的磁盘映像或分区,只需共享主机文件系统。运行代码的脚本如下:
virtme-run \ --kimg bzImage \ --rw --pwd --memory 512M \ --script-sh "<what to run inside kvm>"我们忘记了为我们的fuzzer准备输入语料库!
构建输入语料库
每个fuzzer都需要精心设计的测试用例作为输入,以引导第一个变异。测试用例应该简短,并尽可能覆盖大部分代码。可悲的是我对netlink一无所知,那我们就不准备输入语料库吧……
我们可以要求AFL“弄清楚”哪些输入有意义。这就是Michał在2014年对JPEG所做的,并且很有效。这是我们的输入语料库:
mkdir inpecho "hello world" > inp/01.txt有关如何编译和运行的所有说明都在我们的github上的README.md中。归根到底就是:
virtme-run \
--kimg bzImage \
--rw --pwd --memory 512M \
--script-sh "./afl-fuzz -i inp -o out -- fuzznetlink"运行之后将在屏幕上看到熟悉的AFL打印的信息: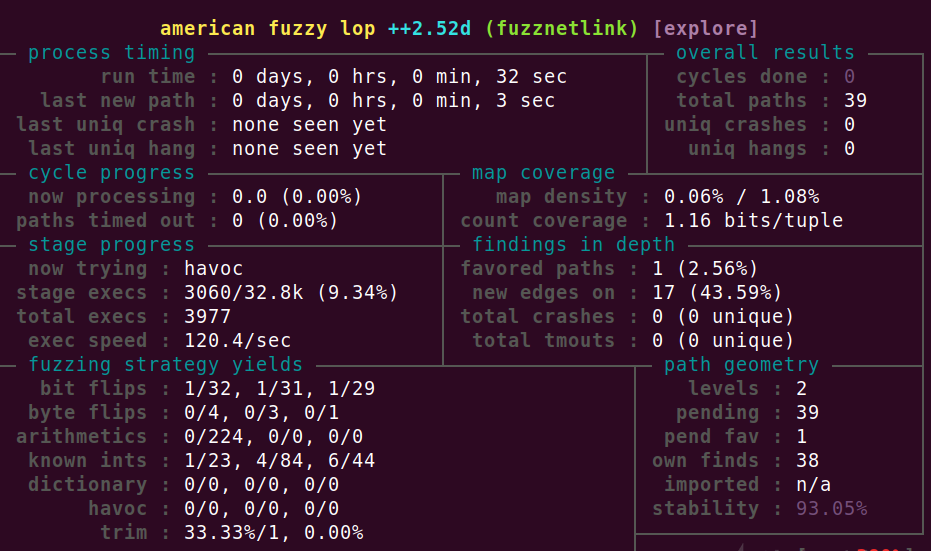
进一步说明
现在你在KVM中有一个自定义的内核并运行了一个基本的基于代码覆盖率的fuzzer。
这么做值得吗?即使只有这个基本的fuzzer,也没有输入语料库,一两天后,fuzzer仍然发现了一个有趣的代码路径:NEIGH: BUG,
double timer add, state is
8(lore.kernel.org/netdev/CAJPywTJWQ9ACrp0naDn0gikU4P5-xGcGrZ6ZOKUeeC3S-k9+MA@mail.gmail.com/T/#u)。使用更专业的fuzzer,一些改进稳定性的指标和一个像样的输入语料库,我们可以期待得到更好的结果。
如果你想了解更多关于netlink套接字的功能,请参阅我的同事Jakub Sitnicki的博客:Multipath Routing in Linux - part 1。在Rami Rosen的Linux内核网络的书中也有一章关于它的内容。
在这篇博客中我们没有提到:
但是我们实现了我们的目标——我们针对内核建立了一个基本但仍然有用的fuzzer。最重要的是可以重复使用相同的机制来fuzz从文件系统到BPF verifier的Linux子系统的其它部分。
我还学到了一个惨痛的教训:调整fuzzer是一项全职工作。正确的fuzzer绝对不是启动它并无所事事地等待crash那么简单。总有一些东西需要改进,调整和重新实现。Mateusz
Jurczyk在上述提到的演讲开头的一句话引起了我的共鸣:“fuzz很容易学,但很难掌握。”
转自先知社区
打赏我,让我更有动力~
 返回:技术文章投稿区
返回:技术文章投稿区
 漏洞文章
漏洞文章

