恶意样本家族分类实践

前记
最近有一个项目需求,需要将恶意样本的厂商描述给汇聚成一组统一的标签,然后后续需要对恶意样本的流量及行为进行特征提取和机器学习来实现恶意样本的检测。
简单点来讲所做的恶意样本家族分类其实就是一个数据清洗和打标签的过程。
数据样本量有90000多条,主要采集于virusshare,这里就以virustotal为例,实际效果其实是一样的
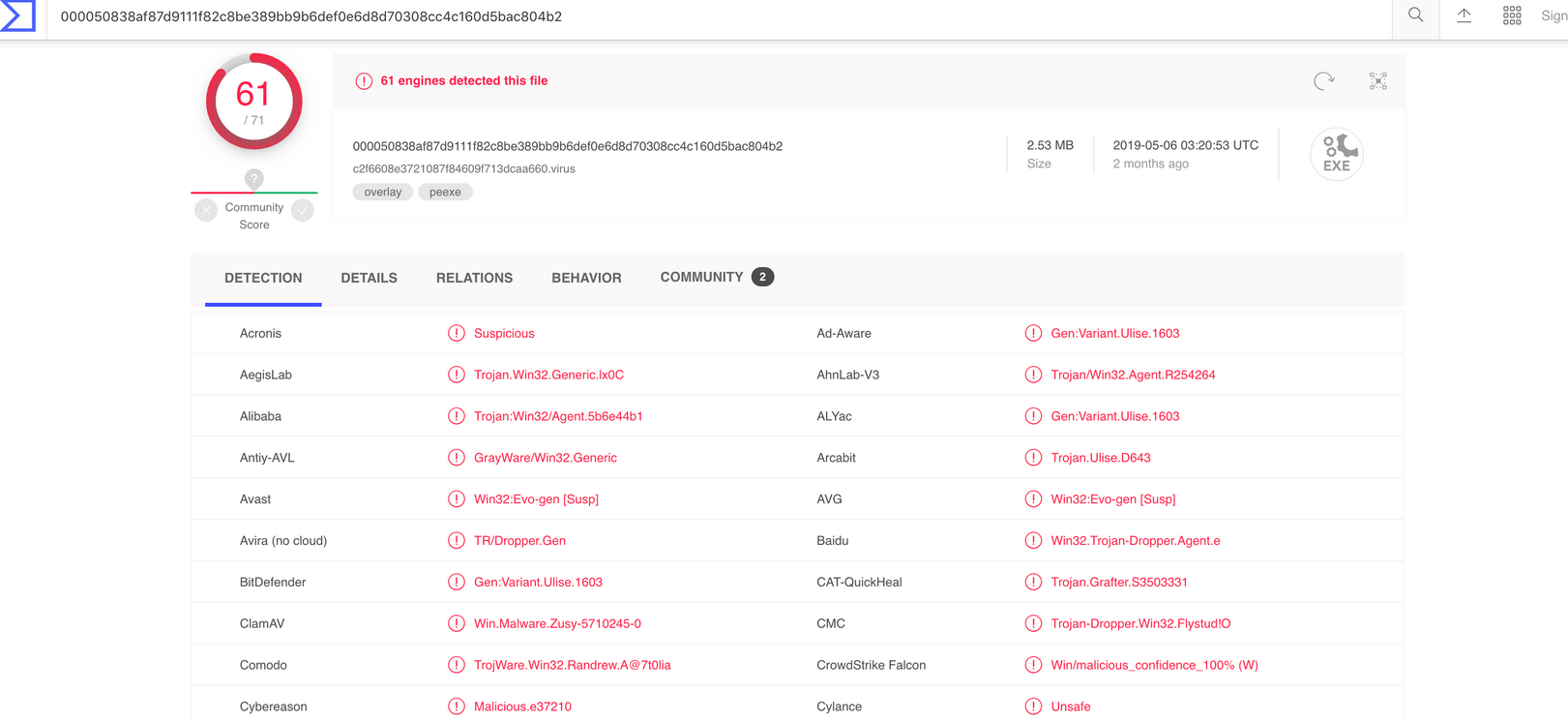
这里大概有大概几十家厂商,但是各家厂商的标签都不一样,甚至连标签描述有时候都不一样,举一个例子,这里Alibaba的样本标签为Trojan:Win32/Agent.5b6e44b1,而CMC的样本标签为Trojan-Dropper.Win32.Flystud!O,那么在输出最终标签时如何进行汇聚和统一成了本文的一个核心要点。
实践思考
入手总是最难的,这里在前期经过比对和一些论文的恶意样本标签参考后,其中标签描述最为规范的是Kaspersky,上图当中Kaspersky的标签描述为“Trojan.Win32.Agent.td”,这里按照顺序进行识别,第一个Trojan为样本类型,这个类型包括Worm、Backdoor、Exploit等具体的攻击类型
第二个Win32则表示样本文件格式类型,这个类型包括Win32、HTML、DOS、AndroidOS等具体的文件格式
第三个Agent则表示具体的家族类型(这里理解上可能有误),在对所有样本进行了汇总后发现第三个家族类型包括CVE-2010-0188、Miner、Mirai等具体的家族类型
最后一个td在比较多家厂商后认为是厂商独有的标记,所以略去,在进行考虑和样本对比后决定对上述三个标签进行提取,最终对每一个样本hash输出一个三元组的标签值['Trojan','HTML','Miner'],即为样本标签。
文本相似度
基于前面的考虑,Kaspersky的样本描述最为规范,所以第一个想到的做法就是对各家厂商做分词,然后对分词结果计算与Kaspersky样本描述的相似度,最后对相似度做累加计算其平均值。
这里的分词其实做法很简单,一般来说对于文本分词可能要用到jieba或者tfidf模型等,但是这里所分词的对象其实就是很简单的一段字符串,所以对特殊符号进行分词即可,如Microsoft厂商的样本描述Trojan:Win32/Randrew!rfn,那么最终经过分词,获得的结果为['Trojan','Win32','Randrew','rfn']

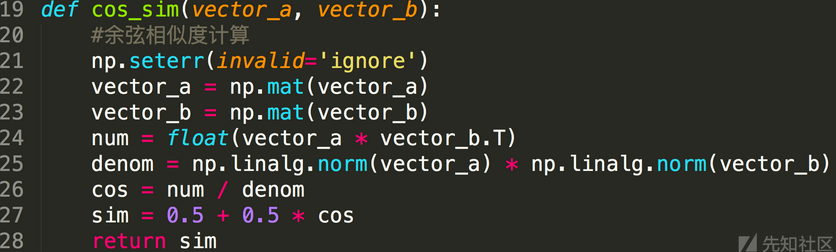
而Kaspersky的分词结果为['Trojan','Win32','Agent','td'],构造词袋模型将分词结果转化为词频数组。那么这里所有的分词结果为['Trojan','Win32','Randrew','rfn','Agent','td'],Microsoft分词数组为[1,1,1,1,0,0],Kaspersky分词数组为[1,1,0,0,1,1],下面使用余弦相似度来计算文本相似度。
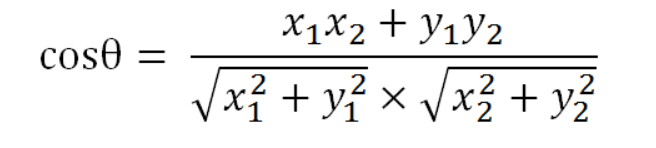
余弦值越大,证明夹角越小,两个向量越相似,所以这里使用余弦相似度来计算每家厂商与Kaspersky厂商的相似度值,最终对相似度值进行累加求平均值
以下附上部分相似度值
'CMC': 0.69692997108170185,
'ESET_NOD32': 0.73625826454412258,
'ALYac': 0.69782949231124958,'Kaspersky': 1.0这里由于是以Kaspersky为基准,因此Kaspersky的相似度为1,那么通过这个相似度计算法我们就可以得到与卡巴斯基样本描述距离从小到大的厂商排名列表。
标签构造实践
接下来开始思考如何取标签,这里首先想到的就是按照前面所得到的的厂商排名列表顺序取标签,那么这里我们就先要构建一个标签字典,这里Kaspersky厂商的官网地址其实是提供了一个具体的标签列表

但是从这个页面当中得到的信息是我们需要构造的标签似乎是有一定规律的,也就是说如果现在有个恶意样本家族,叫XXX,从官网信息中有时候就可以直接判定,这个XXX是什么攻击类型,文件类型是什么,但是在实践过程中发现这么做其实会有很大的误差,上述页面所列举的样本标签其实覆盖很不完全,所以最终也就放弃了对该页面进行爬取,转而对手里的样本进行字典构造。
这里同样对Kaspersky厂商的样本描述进行分词,然后构造了三个标签字典

由于项目较赶,并且一开始在设计的时候没有想太多,默认都是选择相信Kaspersky,所以初期设想的取标签算法简单到了极致,按厂商的文本相似度进行排名,然后顺序取各家厂商的样本描述,对描述进行分词并与标签字典进行匹配,如果匹配上则对输出标签进行填充,当填充完所有标签则退出过程。
这里进行顺序提取的一个原因是Kaspersky的样本描述也会存在为None的情况,那么这时候通过顺序取,有可能当其他厂商能够识别该样本时,也能够对该样本进行标签输出。但是同时忽略了一个问题,那就是当Kaspersky的样本描述为Win32,但是Tencent和Microsoft的样本描述为ASP,这种情况该如何进行抉择?
摩尔投票
其实上面的问题就是原先是进行顺序提取,但是当排名权重高的厂商出现误报,这种情况能不能通过权重设置或者说是投票算法来修正这种情况。
当出现这种情况,其实也不是太大的问题,用投票算法呗。那么问题就来了,用什么投票算法,投票权重怎么设置,问题又被转化为权重怎么设定?这里了解了主流的权重设定法,这类算法一般都是用于有多个指标时对各项指标进行权重设置,如果想套用在当前环境,其实问题也不大,对各家厂商进行多维度的指标统计,然后使用熵权法来设定指标权重,这里的多维度举例来说就是厂商的市值信息、恶意样本数量、恶意样本质量等多维度信息,但是这么做可能就会偏离了安全的本质,当时主要是项目快到交差的时间,这条路当机立断就cut掉了。。
这里继续找投票算法,这里也搜到了很多深度学习的投票算法,但是如果想套用在这个环境,我们就首先需要对样本打上标签,然后进行训练,但是回到工作量的问题,时间太短,厂商太多,并且自己打标签也会出现很多偏差,所以这条路也放弃了。
最后找了一个较为简单的投票算法:摩尔投票算法,也叫多数投票算法,一句话概括就是谁票数多听谁的,但是默认的摩尔投票算法是没有带上权重的,这里小小的改了一下这个算法,票数就等同于前面所计算的文本相似度权重

最终效果就是对厂商标签进行投票选取,哪类标签的相似度权重最高则取谁的。
实践结论
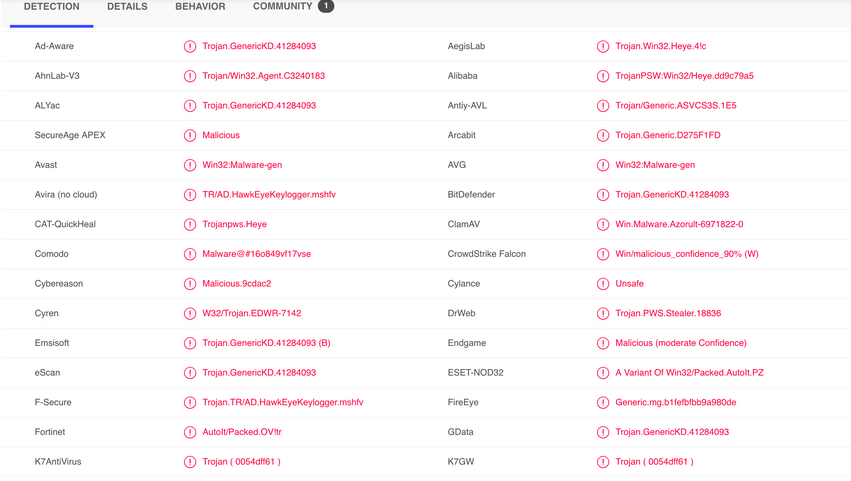
最终输出标签为('Trojan-PSW', 'Win32', 'Heye')

最终输出标签为('Trojan', 'Android', 'TSGeneric')
后记
由于没有准确的标记样本,所以最终实践下来也是只能目测个大概,并且其中的算法选择由于个人的时间和资源的限制,很多想法都没得到实现,只是从简而来,所以相比专业的团队可能会low很多,大家看个热闹~
上述如有不当之处,敬请指出!
转自先知社区
打赏我,让我更有动力~
 返回:技术文章投稿区
返回:技术文章投稿区
 漏洞文章
漏洞文章

